Week 10
Week 10
Due Dates & Links
- Quiz 10 (will post Monday evening) - Due 11:59am March 9, 2022
- Lab Report 5 - Due 5pm March 11, 2021
- All Late Quizzes and Regrades Other than for Skill Demo 2 and Lab Report 5 - Due 5pm March 11, 2021
Lab Tasks
As usual, this may update somewhat before the actual lab time on Wednesday, but it’s a good overview and what we do will be close. You can get started on the lab report immediately, it won’t change aside from clarifications.
Not Writing Parsers
We’ve spent significant time working on markdown-parse this quarter. While some might say too much, the instructor would say we’ve just scratched the surface. Even a problem with a simple specification like this can still be much more complex than we can reasonably implement in 10 weeks (are you convinced that you’re “done”?).
Parsers are a particularly tricky kind of software to get right. To get them truly right, we have to fully understand all possible inputs, even some that might seem irrelevant for our task. We saw that with the interaction of, e.g. [nested[] brackets[][[]]](links), where we had to write entirely new loop structures to manage some of these cases; this doesn’t even get into extra backticks and other formatting interfering with links.
One thing that I highly recommend in your career is not writing parsers unless absolutely necessary. Most well-known markup languages, programming languages, and input formats have perfectly useful open-source, free parsers available. We’ve even seen one – CommonMark!
While in principle it seems like CommonMark has done our job for us, it’s worth seeing what it looks like to actually use it to accomplish something. CommonMark has written a full parser and translator that turns .md files into .html files. This isn’t exactly what getLinks does. How to get from one to the other?
Getting CommonMark
Well, the first thing to do is figure out how to run CommonMark at all. Here’s their Java implementation:
https://github.com/commonmark/commonmark-java
Before we run off and clone it, let’s think a little bit about our goals. We don’t (necessarily) want to edit the source code of CommonMark. It would be nice if we could use it as a library. CommonMark, like JUnit (the other code we’ve often used as a library), is distributed as .jar files. The README, which you can see on their Github webpage, talks about this:
We’ve copied that Maven Central link here for your convenience. Maven is a tool that’s used for tracking, downloading, and updating .jar files associated with Java libraries. We could use to build/import CommonMark, but we won’t take the time for its complexity today. Instead, we’ll just download the correct .jar file directly.
There is a download link next to the top item in the list on Maven; download the .jar file for it:
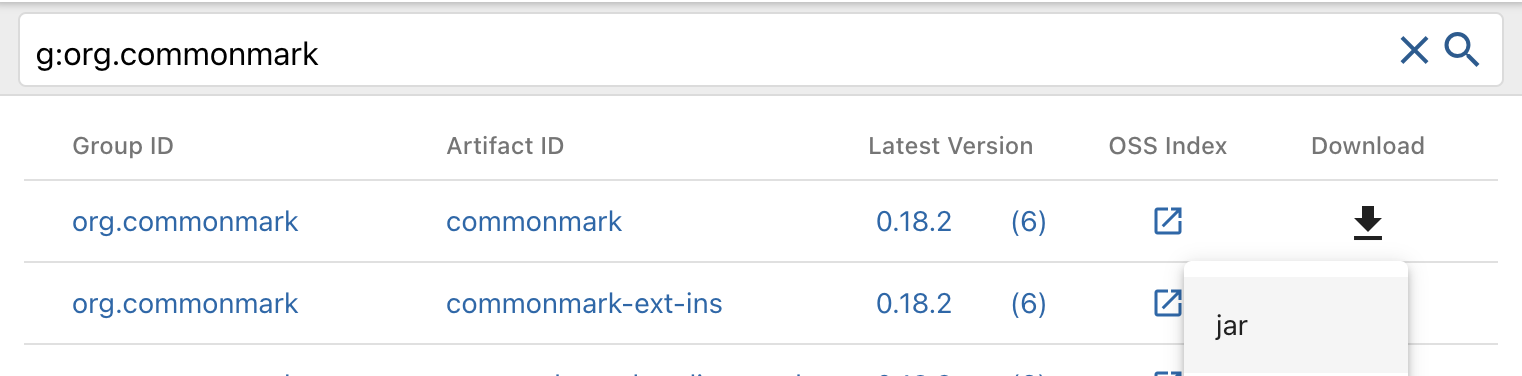
The file you’ve just downloaded is a lot like the .jar file we’ve used for JUnit in its format – we’ll need to use -cp to include it when building and running our program if we use its classes, for instance.
Put the .jar file you downloaded in the lib/ directory of your markdown-parse project.
Running an Example
Let’s make a brand-new file to test out CommonMark and see if we can figure out what it does. Let’s copy one of their examples and try it out. Copy the first example (Parse and Render HTML) from the CommonMark README into a new file called TryCommonMark.java, then compile and run it.
Oops. I got something like this:
$ javac TryCommonMark.java
TryCommonMark.java:5: error: class, interface, enum, or record expected
Parser parser = Parser.builder().build();
^
TryCommonMark.java:6: error: class, interface, enum, or record expected
Node document = parser.parse("This is *Sparta*");
^
TryCommonMark.java:7: error: class, interface, enum, or record expected
HtmlRenderer renderer = HtmlRenderer.builder().build();
^
TryCommonMark.java:8: error: class, interface, enum, or record expected
renderer.render(document); // "<p>This is <em>Sparta</em></p>\n"
^
4 errors
Write in notes: Make sure you’ve copied the code and produced this error.
Turns out the CommonMark folks didn’t give us a full working program with a main method, and so on. They expected us to use our general knowledge of how Java works to take their example and produce a meaningful program out of it. OK, we know how to make a main method. Let’s leave the imports at the top, but take the meaningful code and put it in main, like this:
import org.commonmark.node.*;
import org.commonmark.parser.Parser;
import org.commonmark.renderer.html.HtmlRenderer;
class TryCommonMark {
public static void main(String[] args) {
Parser parser = Parser.builder().build();
Node document = parser.parse("This is *Sparta*");
HtmlRenderer renderer = HtmlRenderer.builder().build();
renderer.render(document); // "<p>This is <em>Sparta</em></p>\n"
}
}
If we run this version, we get another error:
$ javac TryCommonMark.java
TryCommonMark.java:2: error: package org.commonmark.parser does not exist
import org.commonmark.parser.Parser;
^
TryCommonMark.java:3: error: package org.commonmark.renderer.html does not exist
import org.commonmark.renderer.html.HtmlRenderer;
^
TryCommonMark.java:1: error: package org.commonmark.node does not exist
import org.commonmark.node.*;
Of course! We need to include the classpath in order to access all that CommonMark goodness. We could type this out at the command line, but we have a pretty good place to put the classpath (and we know we’ll need it there later) – our makefile!
One thing that can make our lives a little easier here – classpath supports * for use as a wildcard. So we can actually set our CLASSPATH variable to just lib/*:., and that will include all the .jar files in lib/ (along with the current directory .) when we use CLASSPATH in the makefile:
CLASSPATH = lib/*:.
Then we can use a rule like MarkdownParse.class to built this class:
TryCommonMark.class: TryCommonMark.java
javac -g -cp $(CLASSPATH) TryCommonMark.java
(Remember to make sure there’s a <tab> character before the command)
Then we can run:
$ make TryCommonMark.class
javac -g -cp lib/*:. TryCommonMark.java
Cool! It built. If you get an error here, carefully check for typos and completion of the last few steps. Brainstorm together what the cause could be! Retrace the steps, use the error message, and so on to figure out how to make this compile.
Then, let’s try running it:
$ java TryCommonMark
Exception in thread "main" java.lang.NoClassDefFoundError: org/commonmark/parser/Parser
at TryCommonMark.main(TryCommonMark.java:7)
Oops! We need the -cp option to include the CommonMark jar file again. We can use the abbreviated * version to save some typing:
$ java -cp "lib/*:." TryCommonMark
And it… sucessfully prints nothing! Why doesn’t it print anything? How can we make it print something? Change the program so it actually prints the results.
Write in notes: Take a screenshot of your program printing the results. Make a commit with the code so far – don’t forget to add new files! Push, and put a link to the commit in your notes document.
Write in notes: What’s something that was confusing for your group about the example CommonMark provided? What did they assume about you as a user? Do you think other projects with READMEs that you’ll encounter in the future make similar assumptions?
Using CommonMark for Our Task
Printing HTML is great! But it doesn’t accomplish our goal of implementing getLinks. We need to review some of the other examples in the README to figure out how to use this correctly.
Before reading ahead: which example from the CommonMark README do you think is most helpful here, and why?
This example seems promising:
Use a visitor to process parsed nodes
Rather than rendering directly to HTML, it shows how to “visit” every Text element in the parsed markdown. It counts words. We might be interested in doing something similar to collect a list of all links!
First, let’s make sure we can get the example working with our small demo file. Again, it has two parts, the class that implements the visitor and the code that goes in main or some other method that gets the evaluation started:
# this part actually does the computation
Node node = parser.parse("Example\n=======\n\nSome more text");
WordCountVisitor visitor = new WordCountVisitor();
node.accept(visitor);
visitor.wordCount; // 4
# this class can be defined anywhere in the file
class WordCountVisitor extends AbstractVisitor {
int wordCount = 0;
@Override
public void visit(Text text) {
// This is called for all Text nodes. Override other visit methods for other node types.
// Count words (this is just an example, don't actually do it this way for various reasons).
wordCount += text.getLiteral().split("\\W+").length;
// Descend into children (could be omitted in this case because Text nodes don't have children).
visitChildren(text);
}
}
Add these parts to TryCommonMark.java and add a print statement to print the resulting word count – make sure you can get this kind of interaction:
$ make TryCommonMark.class
javac -g -cp lib/*:. TryCommonMark.java
$ java -cp "lib/*:." TryCommonMark
4
Write down in notes once you get this behavior, make a commit and push, and copy the link to the commit into your notes document.
There’s a bit of jargon here that’s common to parsing tools. The parsed markdown string is returned as a Node – so, a tree. A Visitor is a programming pattern for trees where a visitor class can override a visit method with arguments of different types corresponding to types of nodes in the tree. Here, that’s Text, so the visit(Text) method gets called for each text node in the tree.
There’s another node type called Link (I looked it up in the documentation linked from the README).
With this in mind, there are a few steps left to get a full getLinks implementation:
- Try writing another visitor (a class that extends
AbstractVisitor) whosevisitmethod takesLinkarguments, and whose overall purpose is to count the links in a file rather than the number of words. Change the example you have inTryCommonMark.javato use this visitor instead (and make sure it has a link in it!). - Change the visitor so that instead of counting the number of links, it adds each link to an
ArrayList<String>. Test it out usingTryCommonMark. - Move your visitor implementation over into
MarkdownParse.java. Delete the body ofgetLinks(String)(don’t worry, it’s saved ingit), and replace it with code to use the visitor to get the links and return them. Remember to move over any necessaryimportstatements! - Run your tests! Do they all pass? Try running it on all the
test-files/from last week’s lab, and on other, more complex/larger tests.
Write down in notes: How far did you get? Copy the commit with the last checkpoint where you had things running along this progression into your notes.
The main lesson here is that if you find yourself needing to write something like a parser for a project, you probably don’t have to do it yourself. You will likely be better off reading some documentation and using an already-existing tool.
Of course, using existing tools often requires reading documentation, understanding logistics like how to find and import a .jar file, adapting examples for your own use, and so on. These are skills you can practice, ask for help with, and so on in order to broaden the kinds of programs you can write.
Review Game
Having fun is a good way to make memories, including about computing content. For the next 30 minutes of lab, we’ll play a game together reviewing content from CSE15L. Your lab tutor will wrap up the last part with about an hour left to move on to the game, which will be done with the whole lab section (not just your group).
AMA with the Staff
For the last 30 minutes of lab, you’ll have the chance to ask anything (reasonable) to your lab staff (TA and all the tutors for your section). You’ll get a section-specific Google Form for submitting questions, and you’ll also be able to raise your hand and ask questions live. Ask about CS courses, internships, tutoring, research, folks’ experience at UCSD in general and in CSE, and more!
Lab Report 5
In lab 9, you experimented with the many tests provided from commonmark-spec. For this lab report, choose any two tests from the 652 commonmark-spec tests where your implementation (or a representative implementation from your group) had different answers than the implementation we provided for lab 9. Note that this is the implementation in the markdown-parse repository, not the one you did today in lab 10. The tests with different answers should correspond to different bugs – that is, you couldn’t easily fix both with one code change.
Explain:
- How you found the tests with different results (Did you use
diffon the results of running a bash for loop? Did you search through manually? Did you use some other programmatic idea?) - For each test:
- Describe which implementation is correct, or if you think neither is correct, by showing both actual outputs and indicating what the expected output is.
- For the implementation that’s not correct (or choose one if both are incorrect), describe the _bug (the problem in the code). You don’t have to provide a fix, but you should be specific about what is wrong with the program, and show the code that should be fixed.
You can submit your lab report to the “Lab Repor 5” assignment on Gradescope as usual with links to your report page and repository. Make your lab report as a separate page on your Github pages site linked from the index as in past reports.